[database] ClickHouse
개요
- 사이트 / GitHub
- 온라인 분석 처리(OLAP)를 위한 고성능 열 기반 SQL 데이터베이스 관리 시스템(DBMS)
- OLAP 특성
- 데이터 세트는 수십억 또는 수조 행
- 데이터는 많은 열이 포함된 테이블로 구성
- 특정 쿼리에 응답하기 위해 몇 개의 열만 선택
- 결과는 밀리초 또는 초 단위로 반환
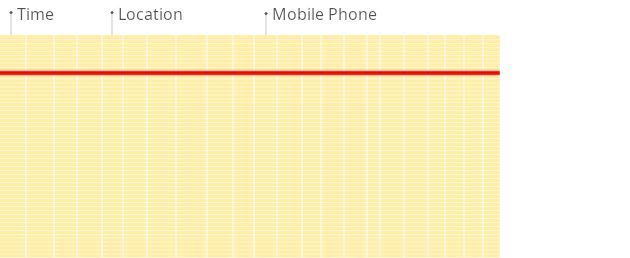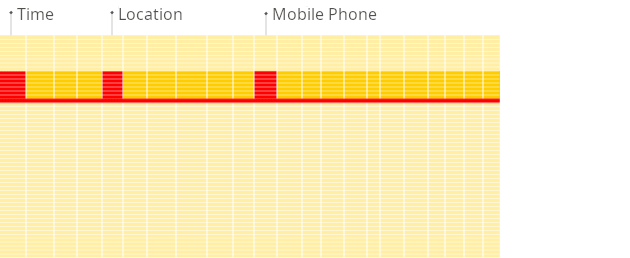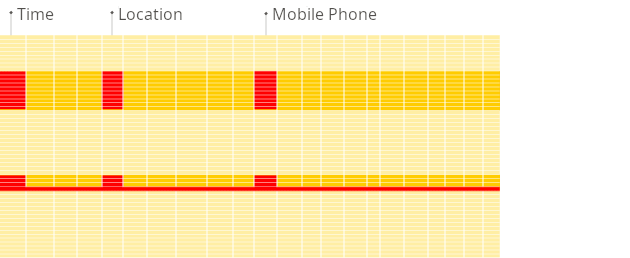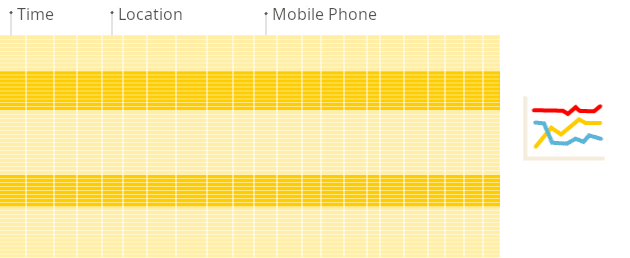
- 행 지향 데이터베이스
- 데이터가 행에 저장
- 열 지향 데이터베이스
- 데이터가 열에 저장
- 빠른 이유
- 열 지향 데이터베이스
- 데이터 압축
- 열이 인접한 행에 대해 동일하거나 유사한 경우가 많기 때문에 행 기반 시스템 보다 압축 비율이 높음
- 벡터화된 쿼리 실행
- 데이터를 열에 저장할 뿐만 아니라 열에 있는 데이터를 처리
- CPU 캐시 활용도가 향상 및 SIMD CPU 명령어 사용 가능
- 사용 가능한 모든 시스템 리소스를 최대한 활용하여 각 분석 쿼리를 최대한 빨리 처리
- 주의사항
- 노드가 여러개일 경우 통합 관리 필요
- 데이터베이스/테이블 생성 시
ON CLUSTER옵션 추가하여 생성- 해당 옵션이 없으면 노드마다 데이터베이스/테이블 생성 필요
- 분산 테이블을 생성하여 조회/삽입
- 분산 테이블이 없으면 접속한 노드에 대해서만 조회/삽입 가능
- 데이터베이스/테이블 생성 시
- 노드가 여러개일 경우 통합 관리 필요
설치
helm install clickhouse oci://registry-1.docker.io/bitnamicharts/clickhouse --create-namespace --namespace clickhouse --values values.yaml- values.yaml
-
resources: requests: cpu: 1 memory: 2048Mi limits: cpu: 2 memory: 2048Mi shards: 2 replicaCount: 2 auth: username: default password: default service: type: NodePort
-
Dashboard / Playground
- NODE IP 확인
echo $(kubectl get nodes --namespace clickhouse -o jsonpath="{.items[0].status.addresses[0].address}")
- NODE PORT 확인
echo $(kubectl get --namespace clickhouse -o jsonpath="{.spec.ports[0].nodePort}" services clickhouse)
- Dashboard
http://${ip}:${port}/dashboard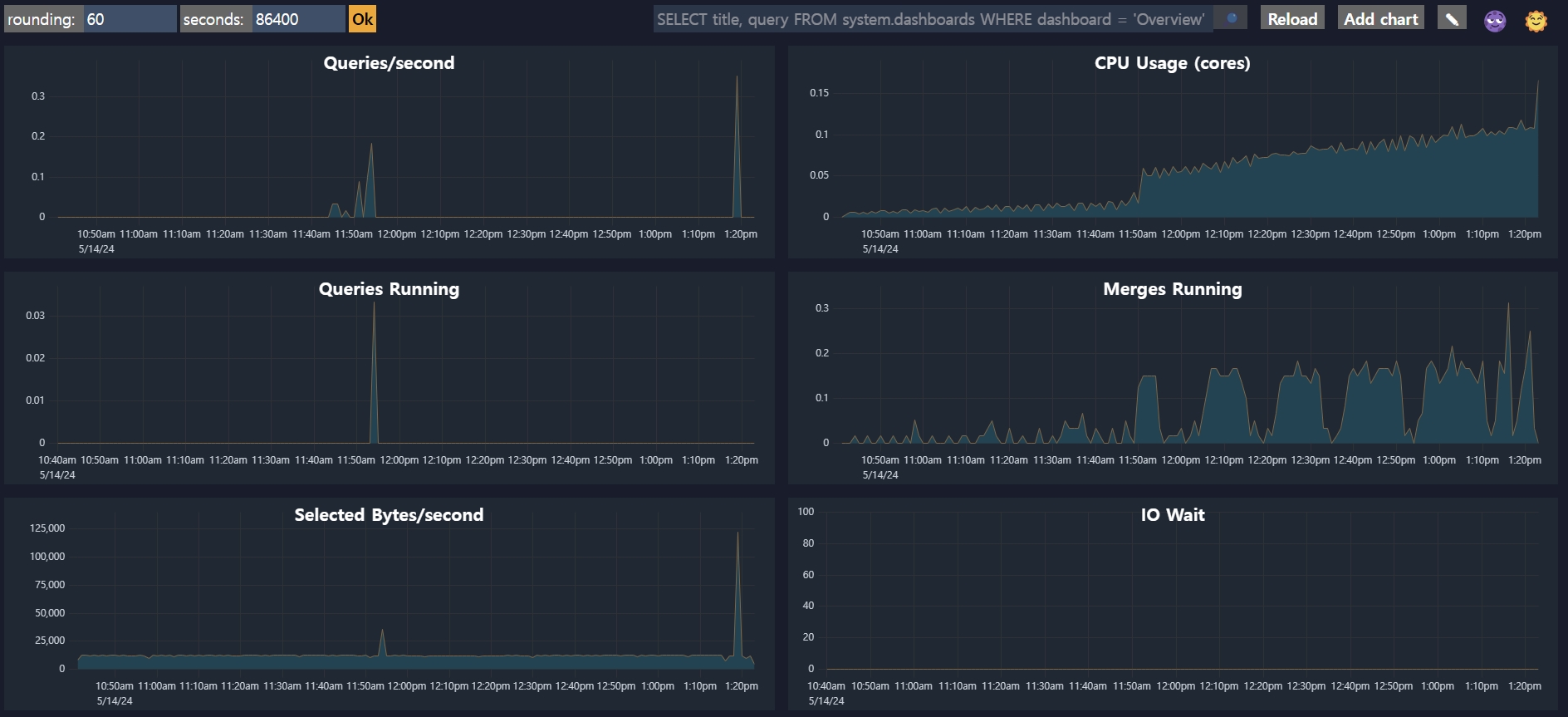
- Playground
http://${ip}:${port}/play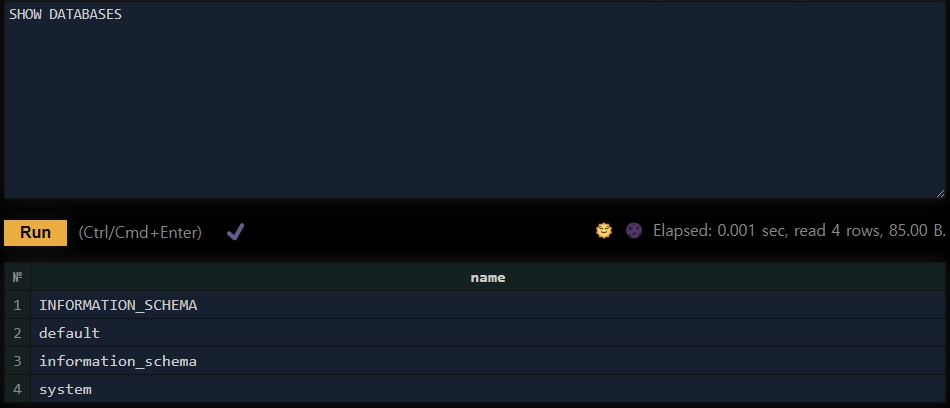
테스트
- 데이터베이스 생성
CREATE DATABASE db01 ON CLUSTER default
- 테이블 생성
-
CREATE TABLE db01.table01 ON CLUSTER default ( `column1` UInt64, `column2` String ) ENGINE = MergeTree ORDER BY column1
-
- 분산 테이블 생성
-
CREATE TABLE db01.table01_dist ON CLUSTER default ( `column1` UInt64, `column2` String ) ENGINE = Distributed('default', 'db01', 'table01', rand())
-
- 삽입
INSERT INTO db01.table01_dist (column1, column2) VALUES (1, 'abc')
- 조회
SELECT * FROM db01.table01_dist
Users and Roles
- RBAC 접근 방식을 기반으로 접근 제어 관리를 지원
- SQL 기반 액세스 제어 및 계정 관리 사용 가능
- access entities
- User account
- Role
- Row Policy
- Settings Profile
- Quota
Backup and Restore
- replication은 하드웨어 오류로부터 보호를 제공하지만 사람의 실수로부터는 보호하지 않음
- 우발적인 데이터 삭제
- 잘못된 테이블 또는 잘못된 클러스터의 테이블 삭제
- 잘못된 데이터 처리
- 데이터 손상을 초래하는 소프트웨어 버그
- …
- 백업 및 복원을 위한 범용 솔루션은 없음
- 1GB의 데이터에 효과가 있는 것이 10TB의 데이터에는 효과가 없을 가능성이 높음
- 종류
- local disk
- S3 Endpoint
- S3 Disk
- AzureBlobStorage Endpoint
